Co-Existence
Using your existing Raw or Staging layer, you can map the required Data from the existing message structures into the CryspIQ® Data model. This enables you to leverage the flexibility of Data model, measure Data Quality and use Natural Language to access your Data. This will provide immediate productivity benefits to your business and enable you to reduce costs.
This provides a visual picture of how CryspIQ® could co-exist alongside your existing Data Platform:
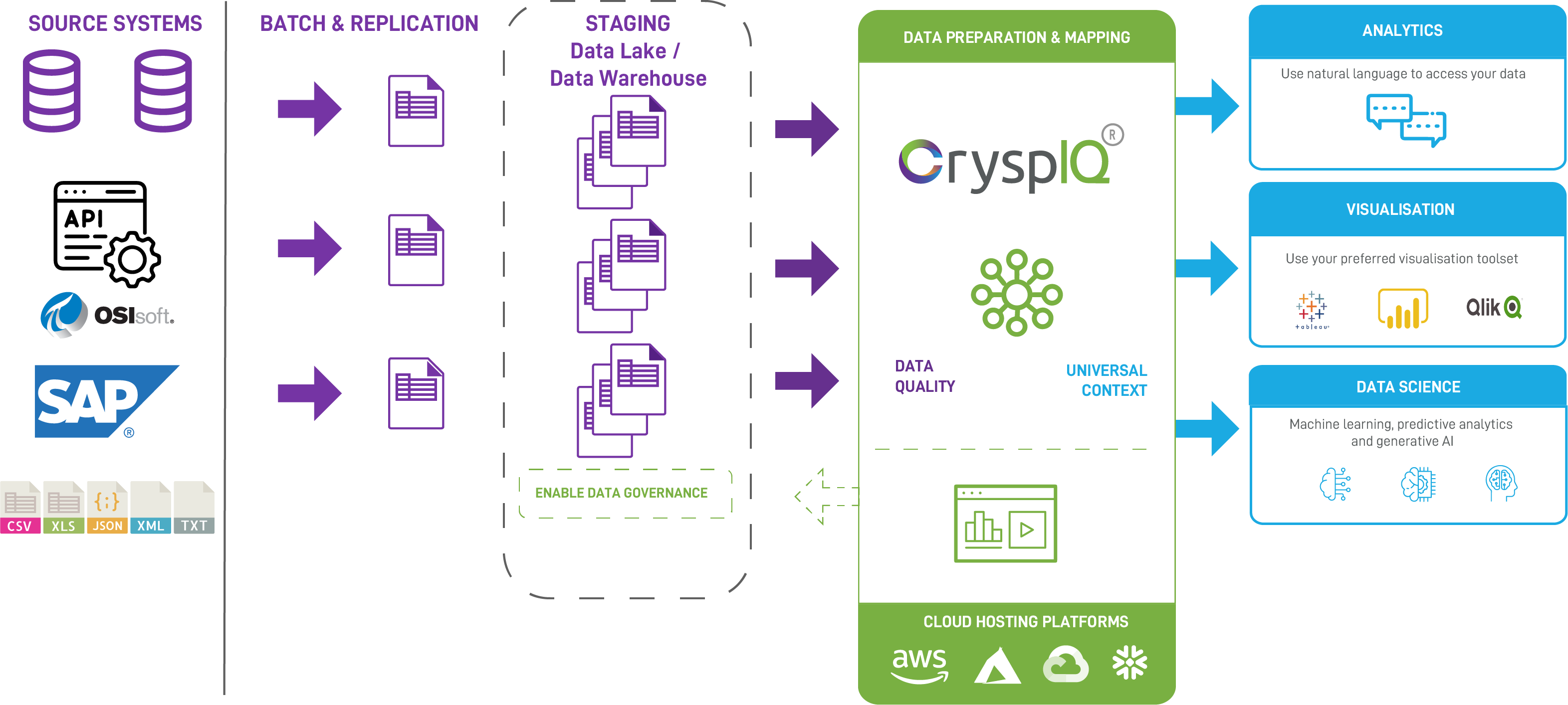
Using Existing Raw or Staging Layers
Most organisations already ingest data into a Raw or Staging layer within modern cloud data platforms such as:
- AWS Data Lake (Amazon S3 with Glue / Athena)
- Snowflake (raw schemas, landing tables, VARIANT data)
- Azure Data Lake / Synapse
- Databricks Lakehouse
These layers typically store data as it arrives, often in its original source structure (for example JSON messages, CSV extracts, or event streams). While this approach works well for ingestion and retention, the data is often:
- Difficult for business users to access
- Inconsistent across systems
- Lacking clear business meaning
- Dependent on specialist SQL or engineering knowledge
CryspIQ® builds on this existing foundation rather than replacing it.
Mapping into the CryspIQ® Data Model
Using the existing Raw or Staging layer, data is mapped from source-specific message structures into the CryspIQ® enterprise data model.
Examples include:
- JSON events stored in Amazon S3 or Snowflake VARIANT columns
- ERP and finance extracts landed in Snowflake staging tables
- Operational data ingested via AWS Glue pipelines
These source structures are mapped into standardised business entities such as Customer, Account, Transaction, or Product—independent of how the data was originally produced.
This approach ensures that:
- Source systems can change without breaking analytics
- Multiple systems can feed the same business entity
- Data definitions remain consistent across the organisation
Flexibility of the Data Model
Unlike rigid star schemas or hand-built data marts, the CryspIQ® data model is designed to be extensible and adaptable.
This enables organisations to:
- Add new attributes without redesigning pipelines
- Support multiple source systems for the same business entity
- Evolve business definitions over time
For example:
- A new data feed landed in Snowflake can be mapped into existing entities without reprocessing historical data
- New event types added to an AWS data lake can be incorporated with minimal effort
This flexibility is particularly valuable in cloud environments where data volumes, sources, and use cases evolve rapidly.
Measuring and Managing Data Quality
Once data is aligned to a common enterprise model, data quality can be measured consistently across all sources.
Typical data quality measures include:
- Completeness of critical attributes (e.g. missing customer identifiers)
- Consistency between systems (e.g. mismatched account statuses)
- Timeliness of ingestion from upstream platforms
- Validity checks on formats and values
In platforms such as Snowflake or AWS, this replaces ad-hoc SQL checks and manual dashboards with standardised, reusable data quality metrics that are directly aligned to business entities.
Natural Language Access to Data
Because the data is structured around a business-aligned model, users no longer need to understand:
- Source system schemas
- Complex table joins
- Platform-specific SQL logic
Instead, business users can query data using natural language, for example:
“Show me customers with incomplete onboarding data last quarter”
CryspIQ® translates these requests into the appropriate queries across platforms such as Snowflake, AWS Athena, or Databricks, while enforcing consistent definitions and governance.
Immediate Productivity and Cost Benefits
By leveraging existing cloud platforms rather than rebuilding them, organisations achieve rapid value:
- Reduced engineering effort by avoiding bespoke data marts
- Lower compute and storage costs by minimising data duplication
- Faster access to insights through self-service analytics
- Improved trust in data through visible and consistent quality metrics
This delivers immediate productivity improvements and measurable cost reductions, particularly in cloud environments where inefficient data usage directly impacts spend.